Tempo stimato per la lettura: 24 minuti
Introduzione
L’avvento del web 2.0, oltre ad essere determinante per la creazione di nuove piattaforme digitali di comunicazione, ha portato anche a rivedere il concetto di privacy e riservatezza dei nostri dati. Oggi è sufficiente accendere il proprio smartphone e iniziare a navigare sul web o accedere ad un social network per venire a patti con tutto ciò: basta veramente poco per perdere il controllo sulle informazioni personali che divulghiamo, a volte inconsapevolmente, in rete. La nostra realtà, così come i nostri interessi, le nostre passioni, vengono trasformati in utilissimi dati riutilizzabili. In questo articolo cercherò di darne una visione globale, attraverso una serie di esemplificazioni pratiche, una prospettiva inedita sul funzionamento del social network più utilizzato al mondo e una definizione del concetto di privacy.
Big Data, Big Problem
Per comprendere il concetto di big data, è doveroso dare una definizione del termine “dato”. La parola dato deriva dal latino datum e significa dono. Viene definito come una descrizione semplice di un elemento. L’elaborazione dei dati comporterebbe la conoscenza di un’informazione. Ogni tipo di dato dipende da due caratteristiche: il codice e il formato che viene impiegato. Nell’ambito informatico, i dati rappresentano un valore, generalmente numerico, che viene processato attraverso l’elaborazione da parte di un calcolatore. Anche il concetto di analisi dei dati è antichissimo. Per analisi dei dati si intende la raccolta e la conservazione di grandi quantità di informazioni per una successiva valutazione.
Di stampo più moderno, invece, è il termine “big data”. Il concetto nasce dall’analista Doug Laney agli inizi degli anni 2000 definendolo come la sintesi di tre V:
- Volume. Ovvero la quantità di dati raccolti da una varietà di fonti, come quelle ricavate dai social media o dalle transazioni commerciali. Se in passato archiviare un’enorme quantità di dati poteva essere problematico, le nuove tecnologie hanno eliminato il problema.
- Velocità. Il flusso di dati arriva a velocità senza precedenti e la gestione di questi è quasi in real-time.
- Varietà. I dati sono disponibili in una grande quantità di formati, dai dati numerici strutturati nei database tradizionali a documenti di testo non strutturati, e-mail, video, audio e transazioni finanziarie.

L’importanza dei big data non deriva dalla loro quantità, bensì dal loro utilizzo. Questo dovrebbe tradursi nell’attuazione di regole sempre più mirate a preservare e tutelare le informazioni personali, per non permettere che la nostra privacy venga violata dalla tecnologia. Ma in un’Era dove i dati sono sempre più “importanti”, la cosiddetta Era dei big data, sono ancora valide ed efficaci queste regole?
Gli algoritmi minacciano la nostra privacy
Il vero pericolo da cui dobbiamo proteggerci sembrerebbe non essere tanto la privacy, bensì la probabilità derivata dagli algoritmi: in qualche modo questa potrebbe influenzare le nostre scelte, inducendo noi stessi a scegliere quello che altri decidono per noi. Risulta quindi necessaria una riflessione sul rapporto che c’è fra la dittatura dei dati e la nostra libertà o volontà di scelta. Pertanto, è indispensabile cambiare il modo in cui vengono controllati e gestiti i dati. Esemplificando, per capire meglio l’insieme, si potrebbe ipotizzare uno scenario in cui ci sono algoritmi in grado di prevedere in anticipo, sulla base dei dati forniti, un attacco di cuore. L’algoritmo o questi dati potrebbero essere venduti alla nostra assicurazione obbligandoci in qualche modo a pagare un premio assicurativo maggiore.
Nel 2012 è stato condotto un esperimento che consisteva nel costruire un algoritmo che riuscisse a prevedere quali auto riscontrassero problematiche al momento della vendita all’asta. Lo studio è stato condotto da una società che organizza gare di data-mining, ovvero la Kaggle. Vennero forniti numerosi dati ai partecipanti di questa gara e quello che emerse fu a dir poco impressionante: attraverso alcune analisi di correlazione venne dimostrato che c’era una relazione fra le automobili arancioni e dei possibili difetti. Più nello specifico, le automobili di colore arancione erano meno soggette ad avere dei difetti, di quasi il cinquanta per cento in meno rispetto ad altre. Lo studio condotto da Kaggle fornisce una spiegazione a questo tipo di correlazione: se il proprietario originale di una macchina sceglieva un colore bizzarro, molto probabilmente la macchina era metaforicamente un mezzo di auto-espressione. Questa sorta di auto-identificazione incrementava la probabilità che il proprietario si prendesse maggiore cura del proprio veicolo.
Algoritmi e social network
Ma cosa si può ricavare dalle informazioni che quotidianamente pubblichiamo, invece, sui vari social network? Queste nuove piattaforme di comunicazione non si limitano ad essere semplici strumenti che ci permettono di comunicare e di rimanere in contatto con amici, ma sono mezzi attraverso il quale vengono recuperati elementi astratti della nostra quotidianità e trasformati in dati.
- Facebook “ha convertito in forma quantitativa, in modo da poter tabulare e analizzare” le relazioni. Questo processo prende il nome di datizzazione. Le relazioni rappresentavano già delle informazioni, ma mai erano state definite come dei dati fintantoché il social network di Zuckerburg non ha sviluppato il grafico sociale.
- Twitter ha datizzato tutti quei sentimenti attraverso un modo, semplice, di condivisione dei propri pensieri.
Gli usi ipotetici di questi dati sono straordinari. Molte start-up hanno cercato di riadattare i dati, come ad esempio il grafico sociale, a degli indicatori di affidabilità creditizia: si basavano sull’idea che persone affini si cercassero. I ricchi database derivati dai social network potrebbero quindi divenire la base di nuove attività commerciali. Un esempio? Il social network creato dalla Obvious Corporation ha stipulato accordi con alcune società commerciali, come DataSift e Gnip per la vendita dei dati degli utenti iscritti. Derwent Capital e MarketPsych sono due fondi speculativi che hanno analizzato i tweet come segnali d’investimento nel settore azionario. Sarà compito dei modelli algoritmici ricercare tutte le correlazioni non ancora conosciute da un set di dati, per ricavare un possibile profitto. Decide.com è un’altra società che si occupa di raccogliere dati, ma su larga scala: l’azienda ha una “mentalità orientata al big data”.
Secondo Huberman, la frequenza dei tweet su uno specifico argomento poteva prevedere molte cose, fra cui gli incassi derivati da un film. Queste conclusioni derivano dallo sviluppo di un algoritmo che assumeva come input la frequenza con cui venivano postati nuovi tweet e forniva come output la previsione sul successo di un film. Questo modello risultava molto più attendibile rispetto ai soliti e generici strumenti predittivi. Successivamente, in uno studio condotto da Science, vennero analizzati circa 510 milioni di tweet in un arco temporale di circa due anni, pubblicati da 2,4 milioni di persone sparse su un’area di 84 paesi.

Le informazioni prese in considerazione durante lo studio erano:
- il testo dei tweet;
- la lingua degli utenti;
- il numero di follower;
- il numero dei seguiti;
- la geolocalizzazione degli utenti.
Questo studio era volto a dimostrare che gli stati d’animo quotidiani e settimanali avevano uno sviluppo analogo fra le varie culture. Per la prima volta erano stati datizzati dei sentimenti. Oggetto della datizzazione, oltre ai nostri sentimenti e atteggiamenti, è anche il comportamento umano. Salathè e Khandelwal in uno studio riguardante le vaccinazioni antinfluenzali, hanno dimostrato come attraverso l’analisi dei tweet si potesse scoprire che i comportamenti delle persone erano allineati alla probabilità di sottoporsi al vaccino.
Oggi i dati vengono utilizzati per scopi sempre più innovativi, sono il cosiddetto valore opzionale.
Correlazione e Causalità
Precedentemente si è parlato di correlazioni, ma cosa sono? Il concetto di correlazione non è da confondere con quello di causalità. Se con il termine correlazione si fa riferimento ad una relazione tra due (o più) variabili che cambiano insieme, la causalità viene definita come una relazione tra due (o più) variabili dove una variabile causa l’altra. Da secoli è in corso un dibattito filosofico sul concetto di causalità: se tutto quello che facciamo fosse causato da un qualcosa di cui ne siamo inconsapevoli, allora la volontà umana non esisterebbe più. Ogni decisione, ogni azione che intraprendiamo sarebbero il risultato di una reazione di cause. I big data hanno trasformato i modi attraverso il quale noi esseri umani interpretiamo il mondo, ovvero tramite una causalità molto rapida e illusoria oppure in modo lento e metodico.
Secondo Daniel Kahneman, uno psicologo, le persone hanno due processi mentali distinti:
- uno che permettere di arrivare a delle conclusioni in pochi secondi;
- un altro, invece che è più lento, in quanto andiamo ad analizzare più in profondità una questione.
A volte però la nostra mente sbaglia, affidando al pensiero più veloce un’analisi che avrebbe dovuto essere esaminata in profondità, portandoci a delle conclusioni erronee, vedendo delle causalità immaginarie. Le correlazioni, così come alcune analisi non causali, sono rapide e parsimoniose. Le correlazioni sono molto utili anche perché ci guidano in una direzione specifica nel processo di analisi: ci indicano quali elementi sono legati fra loro, se c’è un tipo di relazione e perché esiste questa connessione. È grazie alle correlazioni che siamo in grado di capire quali elementi saranno essenziali al fine di verificare una certa causalità.
Conclusioni
I big data stanno rivoluzionando il nostro modo di vivere, ci forzano a prendere nuovamente in considerazione tutto ciò che riguarda il nostro processo decisionale. La veemenza delle correlazioni mette in discussione una visione del mondo basata unicamente sulla ricerca delle cause. Se prima il sapere era la sintesi di tutte le nostre conoscenze passate, ora è la capacità di prevedere il futuro attraverso algoritmi e analisi dei dati. I dati diventano così il perno della nostra economia e società, supportati da strumenti sempre più capaci, intelligenti e veloci. I big data ci rendono vulnerabili, rendendo inefficaci quasi tutti quei sistemi legati alla tutela della privacy. Dobbiamo far sì che l’attenzione in merito alla responsabilità della privacy venga spostata dall’utente, da proteggere, agli effettivi utilizzatori dei dati per favorire un utilizzo più responsabile.
Come priva(r)cy della nostra riservatezza
Nel 1860 Samuel Warren e Louis Brandeis, definirono il termine di privacy come il diritto di essere lasciati da soli. La privacy è un concetto in continua evoluzione che copre diversi ambiti quali, ad esempio, la cultura e la tecnologia. Oggi potremmo definire la privacy come un qualcosa di estremamente complesso: gli sviluppi tecnologici hanno rivoluzionato tutto ciò che concerne la riservatezza.
Un approccio differente al concetto di privacy è quello sostenuto dal fondatore e amministratore delegato di Facebook, Mark Zuckerberg:
“la privacy non è più una norma sociale rilevante.”
Risulta evidente che la privacy possa risultare scomoda a un social network, come Facebook, ma come sottolinea la sociologa, psicologa e tecnologa statunitense Sherry Turkle cosa sarebbe la nostra intimità, la democrazia e il pensiero libero senza la privacy?
Successivamente alle rivelazioni di Edward Snowden la percezione che abbiamo sui dati è in qualche modo cambiata: se prima, gli annunci pubblicitari che apparivano quando visitavamo una pagina ci sembravano utili, ora invece acquisiscono una connotazione negativa che mette in luce la tracciatura di tutti i nostri comportamenti in rete. Se non vogliamo che i servizi di cui fruiamo in rete, come Facebook, ci manipolino o vengano a conoscenza di alcune nostre preferenze non dovremmo più utilizzarli o limitarci alla sola osservazione delle informazioni. Ma è davvero questa la direzione che dobbiamo prendere?
Così come un avvocato è tenuto a rispettare il segreto professionale del proprio assistito, anche le società che raccolgono i nostri dati dovrebbero tutelarli e tutelarci, in modo tale che gli individui abbiano il pieno controllo su un ipotetico loro utilizzo. Come afferma la Turkle,
“siamo stati portati a credere che rinunciare ai dati personali sia uno scambio equo per ottenere servizi gratuiti e suggerimenti utili; questa discutibile nozione di scambio equo ha rallentato la nostra capacità di pensare criticamente”.
Questo ci ha portati a pensare che in futuro sarà sempre più impossibile avere una privacy online completa, che nessuna modifica comporterà una maggiore chiarezza.
I meccanismi di tutela della privacy e la loro efficacia
Tutte le informazioni che postiamo in rete contengono dei dati personali da tutelare? Teoricamente le analisi su questi dati, come ad esempio quelli trasmessi da macchinari di produzione, non presentano alcun tipo di rischio alla privacy. È effettivamente così?
La maggior parte dei dati che produciamo includono sempre una componente personale che le aziende sono sempre più intenzionate a conservare e riutilizzare. Le informazioni personali riconducibili ad un individuo potrebbero anche essere il risultato di processi non espliciti. Nei big data, diversamente dagli small data, la quantità e la varietà di dati nettamente superiori facilita questo processo di re-identificazione degli utenti. Le strategie adottate per preservare la privacy degli utenti come la dissociazione, il consenso informato individuale e l’anonimizzazione oggigiorno hanno perso la loro efficacia.
Secondo Paul Ohm, professore di diritto all’University of Colorado, non c’è una soluzione alla problematica della privacy. Quando siamo a conoscenza di un enorme quantitativo di dati l’anonimizzazione non è possibile, così come anche le interconnessioni fra le persone (quello che precedentemente si è definito come grafico sociale) risulta vulnerabile al meccanismo di de-anonimizzazione. I big data oltre a sorvegliarci, rendono anche obsolete molte forme di tutela della privacy, come la tecnica dell’anonimato. Con il passare del tempo le previsioni ricavate dall’analisi dei dati diventeranno sempre più inarrestabili, traducendosi in una vera e propria ossessione verso questi, motivata dalla loro potenza assoluta e illimitata. Dobbiamo quindi evitare di avere una fiducia cieca nei confronti dei dati. Secondo alcuni ricercatori sono determinabili delle correlazioni attraverso i dati presenti in un database anche se stati opportunamente anonimizzati. A favore di tutto ciò c’è una dimostrazione matematica: attraverso una reiterazione di query al database è possibile risalire alla persona che ha generato quel set di dati dalle informazioni raccolte in forma anonima.
La privacy differenziale
Un metodo per prevenire e tutelare i nostri dati viene fornito dalla privacy differenziale. Questa tecnica consiste nel confondere deliberatamente i dati dai noi trasmessi, in modo tale che ogni singola query non porti alla rivelazione esatta di un risultato, ma ad una sua approssimazione. Questo dovrebbe rendere difficile o perlomeno costoso quel processo atto ad identificare una persona. Facebook si avvale di questa metodologia quando vende le informazioni dei suoi iscritti ad investitori pubblicitari. Cynthia Dwork, ricercatrice di Microsoft, e Aaron Roth, il professore di informatica alla University of Pennsylvania, sono gli autori di Algorithmic Foundations of Differential Privacy, ovvero una tecnica di privacy differenziale. Il metodo implementato dai due ricercatori consiste in tre operazioni che hanno come obiettivo quello di manipolare i dati, introducendo del “rumore” per nascondere l’identità di chi ha generato quelle informazioni:
- La prima operazione, chiamata hashing, attraverso una chiave crittografica, converte i dati in una stringa di caratteri casuali. Vengono cifrati i dati sensibili risiedenti sul dispositivo e ogni tipo di comunicazione fra quest’ultimo e l’azienda.
- Il secondo step è il subsampling, in cui viene presa in considerazione solo una parte dei dati ottenuti.
- Il terzo processo è la noise injection, attraverso il quale viene inserita una quantità di rumore nelle informazioni, per nascondere l’identità dell’utente che le ha generate.

Questa tecnica è stata adotta dalla Apple a partire dalla tecnologia iOS 10. Per le aziende questo significa poter ricavare più valore dai dati, ma tutelando l’identità dell’utilizzatore.
Privacy: la prospettiva secondo Sherry Turkle
La psicologa statunitense, Sherry Turkle, ha una visione ottimista sul fatto che ci sarà un momento in cui tutte le persone, connesse al mondo online, cominceranno ad esigere la loro privacy, a volere indietro un mondo basato sulle relazioni offline, con persone reali. Nonostante la tecnologia sia una prova difficile, perché ci permettere di essere quello che non siamo nella realtà, di creare un’ombra elettronica, non è una sfida impossibile. La speranza della Turkle è far sì che ognuno di noi reclami il proprio bisogno di privacy:
“aprire una conversazione sul ripensamento della Rete, sulla privacy e sulla società civile non è affatto una nostalgia arretrata. Sembra parte di un sano processo di democrazia che definisce i suoi spazi sacri.”
Ci si può fidare di Facebook? Davvero, una volta visto dall’interno, “ci piace”?
Siamo sempre inondati da informazioni sui social network da un punto di vista “esterno”, ma cosa ne pensa chi ci lavora dentro? chi si confronta ogni giorno con i meccanismi innescati da queste nuove piattaforme di comunicazione? Una possibile risposta a questi quesiti ci viene fornita da Katherine Losse.
Chi è Katherine Losse?
Katherine Losse è l’autrice del libro “Dentro Facebook” ed era anche una dipendente di Facebook. L’autrice ha iniziato la sua carriera come impiegata presso il servizio clienti, il cui compito era quello di dare un supporto alle infinite domande dei clienti e gestire gruppi offensivi. L’ultimo anno di lavoro in Facebook, Katherine Losse scrisse a nome di Mark Zuckerburg, diventando la sua voce pubblica, insomma divenne una sorta di scrittore fantasma di Zuckerburg.
Quello che emerge fin dalle prime pagine, del suo libro “Dentro Facebook”, è una totale noncuranza di tutto ciò che riguarda il concetto di privacy, in particolare la gestione delle e-mail relative agli account degli utenti. Il team di informatici-programmatori di Facebook infatti era in possesso di una sorta di “passepartout”, più precisamente di una password universale, attraverso il quale era possibile entrare nel profilo di qualsiasi utente e avere così accesso a tutto ciò che riguardava la sua identità e i suoi messaggi. Solo successivamente, un anno dopo, furono prese delle precauzioni a favore di misure di sicurezza più serie: per accedere a quelle informazioni era necessario autenticarsi come dipendete di Facebook. Un ulteriore mancanza dell’azienda era la superficialità relativa al trattamento dei dati: dopo ventiquattro ore gli sviluppatori avrebbero dovuto cancellare dai server i dati degli utenti a loro disposizione, ma non c’era modo di sapere se effettivamente questi dati venissero eliminati.
Gli amministratori di sistema della piattaforma di “Zuckerburg” erano davvero esenti da qualsiasi limitazione di riservatezza! Erano in possesso di informazioni quali l’ultima login, i post cancellati e il riferimento geografico al momento dell’accesso. Nel libro, K. Losse parla anche di uno strumento dal sapore Orwelliano: proprio come il personaggio fittizio del romanzo “1984” di Eric Arthur Blair, noto con lo pseudonimo di George Orwell, che tiene sotto controllo ogni individuo, anche “Facebook Stalker” informava il personale di Facebook su chi aveva guardato un profilo. Facebook stava diventando “un grande campo di battaglia per il controllo dello sguardo”.
Il lancio dello strumento “News Feed” suscitò fra gli utilizzatori del servizio molte perplessità. News Feed analizzava e rielaborava i dati immessi dagli utenti. La Losse descrisse questo come
“una narrazione articolata, scritta e illustrata da una macchina: non eravamo più noi gli autori esclusivi della nostra storia, ora dovevamo fare i conti anche con una nuova specie di autorialità algoritmica”.
Nella maggior parte delle volte le informazioni pubblicate da News Feed sulla nostra bacheca, sebbene formalmente corrette, risultavano essere terribilmente inadatte e immediate. La differenza fra la progettazione dell’algoritmo e la narrazione di storie “vere” era palese: News Feed ci informava su notizie che non avremmo saputo, in quel modo così rapido, freddo e indolore, nella vita reale, come ad esempio il non essere stato invitato ad una festa o la fine di una storia d’amore. Appena lanciato, il servizio clienti di Facebook, venne sommerso da migliaia di e-mail dove gli utenti denunciavano di essere stati ingannati, messi a nudo. Katherine Losse, nel suo libro riporta numerosi esempi, fra cui lo sfogo di un ragazzo:
“Mi sono lasciato con la mia ragazza proprio ieri, e grazie al vostro News Feed ora nel campus lo sanno tutti! Come pensate che si senta la gente quando vede pubblicati i fatti suoi senza volerlo?”
Quello che emerge è un social network estremamente indifferente alla correttezza, ma soprattutto alla propria sfera individuale. Ancora una volta, ciò che veniva messo al primo posto erano i dati, indipendentemente da come questi venissero utilizzati o quali effetti avrebbero potuto produrre.
Lo scopo dell’azienda era quello di incrementare il numero di iscrizioni al social network. Per rendere tutto ciò possibile, Zukemberg incaricò i programmatori di realizzare uno strumento chiamato “Dark Profiles”. Dark Profiles aveva l’obiettivo di creare profili nascosti per persone che non erano ancora iscritte a Facebook, ma che erano state nominate o “taggate” nel social network. Le persone che venivano aggiunte al social network venivano a conoscenza dell’esistenza del profilo già creato e attivato solo dopo la registrazione. Si cercava in tutti i modi di creare una sorta di archivio che raccogliesse potenzialmente tutte le persone del mondo.
“Come annunciato in aprile, Facebook ha aggiornato gli indirizzi e-mail per renderli più coerenti sulla piattaforma. Oltre ad avere creato un indirizzo personale per ogni utente, Facebook ha lanciato una nuova impostazione per dare agli utenti la possibilità di decidere quale indirizzo preferiscono rendere visibile sulla propria Timeline. Dal lancio della Timeline gli utenti hanno avuto la possibilità di controllare quali post pubblicare o nascondere in Bacheca; oggi questa possibilità è stata estesa anche ad altre informazioni, a partire dagli indirizzi e-mail”.
 Questo è il comunicato stampa attraverso il quale l’azienda diffuse la notizia della sostituzione degli account e-mail: anche se questa novità fosse già stata preannunciata qualche mese prima della messa in atto, nessun iscritto al social network poteva immaginare che il team di Mark Zuckerberg procedesse alla sostituzione degli account e-mail senza informare gli utenti. La sostituzione delle mail personali, di circa 900 milioni di iscritti, in indirizzi di posta elettronica con desinenza “@facebook.com” si può considerare un altro caso in cui gli utenti sono stati usati a favore di una strategia che chiaramente ha dei risvolti commerciali: garantire una maggiore visibilità.
Questo è il comunicato stampa attraverso il quale l’azienda diffuse la notizia della sostituzione degli account e-mail: anche se questa novità fosse già stata preannunciata qualche mese prima della messa in atto, nessun iscritto al social network poteva immaginare che il team di Mark Zuckerberg procedesse alla sostituzione degli account e-mail senza informare gli utenti. La sostituzione delle mail personali, di circa 900 milioni di iscritti, in indirizzi di posta elettronica con desinenza “@facebook.com” si può considerare un altro caso in cui gli utenti sono stati usati a favore di una strategia che chiaramente ha dei risvolti commerciali: garantire una maggiore visibilità.
Nei capitoli finali del libro Katherine Losse descrive il social network Facebook come una “tecnologia della disumanizzazione” in cui si cercava di rendere sempre più efficiente tutto ciò che gli utilizzatori della piattaforma potevano fornire, manipolandoli, senza prendere in considerazione le loro emozioni e i loro sentimenti.
Facebook: i dati prima di tutto
LIWC2007 e l’analisi dell’umore
Come comprova della manipolazione delle emozioni degli iscritti a Facebook, c’è uno studio condotto dalla Proceedings of the National Academy. Le ipotesi alla base dello studio si basavano sui feed di aggiornamento, che tutti noi osserviamo tutte le volte che apriamo l’applicazione o accediamo a Facebook. Questi potrebbero essere in grado di influenzarne il nostro stato d’animo, il nostro umore e quindi anche alcuni nostri comportamenti. Per verificare tutto ciò, i sociologi manipolarono gli aggiornamenti e quindi le notizie che apparivano sulle bacheche di circa 700.000 utenti del tutto ignari, per una settimana.
Tutto ciò fu possibile grazie ad un software, chiamato LIWC2007 (Linguistic Inquiry and Word Count), che andava ad analizzare tutti i post di Facebook, estrapolando alcune parole chiave determinanti nell’identificazione dell’umore dell’utente. Queste informazioni vennero poi utilizzate per manipolare le bacheche degli utenti-cavie, dando maggiore visibilità ai post positivi o negativi. Nei giorni successivi è stato analizzato il loro comportamento online. Emerse che gli utenti esposti ad uno stream di notizie positive, tendevano a condividere notizie positive, mentre post negativi presupponevano una pubblicazione di commenti tristi.
Facebook si difende da ogni sorta di accusa in merito alla violazione della privacy, sostenendo di aver agito nel pieno rispetto dei termini di servizio di Facebook. La negligenza sarebbe quindi da parte degli utenti, che non avrebbero letto le condizioni di utilizzo del social network che regolano il rapporto tra gli utenti e l’azienda. Di parere contrario è Grimmelmann, docente di diritto all’Università del Maryland, che invece condanna Facebook di aver violato più di una legge non informando gli utenti dell’esperimento.
Facebook VS Tribunale Belga: cookie e smart pixel tracciano gli iscritti
Nel 2005 è iniziato un processo, conclusosi quest’anno (2018), che aveva come attori Facebook e il tribunale belga. Oggetto della sentenza era la violazione della privacy degli utilizzatori del social network. In conclusione, la sentenza stabilì che Facebook violava la legge sulla privacy definita dall’Unione Europea e pertanto doveva cessare la raccolta dei dati degli utenti belgi e procedere con la cancellazione di tutti i dati precedentemente raccolti. Per tracciare gli utenti, iscritti e non, Facebook utilizzava diversi strumenti fra cui cookie e smart pixel. Il fine della raccolta dei dati era puramente commerciale. Ma il fulcro di tutta la vicenda non è tanto come i dati venissero riutilizzati, quanto la mancanza da parte del colosso informatico di un’informativa trasparente. La corte belga ha infatti dichiarato che Facebook
“non informa in modo sufficiente sulla raccolta delle nostre informazioni, sul tipo di dati che raccoglie, su ciò che fa con quei dati e per quanto tempo li memorizza. […] non ottiene il nostro consenso per raccogliere e archiviare tutte queste informazioni”.
Attraverso la sessione attiva dell’utente e i tasti “mi piace” e “condividi”, Facebook era in grado di ricavare i dati sulla navigazione anche quando l’utente faceva visita ad un altro sito. Questo permetteva a Facebook di avere una profilazione esaustiva, utilizzata successivamente per le inserzioni pubblicitarie.
L’incitazione al voto
Un ulteriore studio, è quello condotto, nel 2012, in occasione delle elezioni presidenziali. Facebook incitò alcune persone a recarsi alle urne a votare, mostrando nella loro bacheca che gran parte dei loro amici avevano già votato. Questo situazione venne presa in esame da Jonathan Zittrain, un professore americano di diritto applicato al mondo web, che valutò l’influenza dei social media sull’affluenza alle urne. Lo stimolo per spingere le persone a votare consisteva in:
- un grafico che conteneva un link per ricercare le urne più vicine;
- un pulsate da cliccare non appena si aveva votato;
- le foto profilo di sei amici di Facebook che avevano già fatto lo stesso.
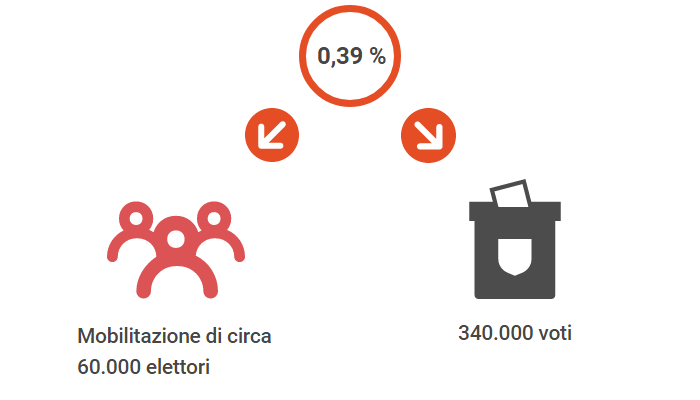
Alcuni politologi, grazie alla collaborazione di Facebook, hanno messo in atto questo studio facendo apparire nelle News Feed di decine di milioni di utenti il grafico sopracitato. Come test di controllo si era deciso di mostrare ad altri utenti un messaggio generico che li informava di andare a votare. Per valutare se ci fosse stato un incremento di affluenza, lo step successivo dello studio riguardò un’attenta analisi dei dati. Le informazioni riscontrate dal social network furono incrociate a numerosi riferimenti come i nomi dei soggetti presi in esame e le affluenze relative al giorno del voto dai distretti di tutto il paese. Le conseguenze furono le seguenti: gli utenti notificati del voto dei loro amici hanno registrato uno 0.39% in più di probabilità di andare a votare rispetto al gruppo di controllo. Questo piccola percentuale di affluenza si traduceva in moltissimi nuovi voti. Quelle che emerse dalle analisi fu una mobilitazione di circa 60.000 elettori, che grazie ad una reazione a catena, alla fine ha determinato altri 340.000 voti in quel giorno. Questo studio dimostra come un social network possa alterare l’affluenza alle urne. A questo punto risulta spontaneo chiedersi se attraverso la manipolazione delle nostre bacheche dei social network sia possibile anche andare a modificare una preferenza di voto.
In accordo con le conclusioni dell’esperimento sopracitato, sono le affermazioni di Jeff Hammerbacher, primo data scientist di Facebook. Analizzando i dati scoprì che gli utenti erano maggiormente intenzionati a compiere una specifica azione se avevano visto anche dei loro amici farlo. Pertanto, Facebook ha riprogettato l’intero sistema al fine di rendere maggiormente visibile le attività compiute dagli amici, come ad esempio cliccare un’icona o pubblicare un contenuto. Questo innescato una sorta di reazione a catena fra gli iscritti, incrementando il numero di contenuti e quindi di dati.
What Facebook knows about You?
ProPublica, un’organizzazione americana no profit statunitense, ha analizzato attraverso un’estensione le informazioni che Facebook è a conoscenza su di noi. Ovviamente l’uso del social network non è del tutto gratuito, ma ha un costo e non indifferente. What Facebook knows about You è un’estensione di Google Chrome che permette a chi decide di installarla di vedere il nostro profilo Facebook da una prospettiva differente, ovvero quella che appare agli investitori pubblicitari. Il risultato è sorprendente: età, genere, lavoro, luogo di residenza, preferenze, passioni, e hobbies sono le informazioni che delineano il nostro profilo. Ci sono anche tutte quelle informazioni che sono inferite sulla base di ciò che Facebook sa su di noi. Facebook, però non si limita a farci un profiling sulla base dei contenuti che pubblichiamo sulla piattaforma digitale, ma acquista da altre aziende informazioni su di noi.
Conclusioni
Come fare quindi se non vogliamo emigrare dal mondo online, lasciare i social media? Servirebbe che il nostro contratto, con queste aziende che operano con i big data, venisse riscritto in termini di maggiore trasparenza. L’avvento del Regolamento Europeo in materia di protezione dei dati personali, dovrebbe dare una nuova dimensione alla problematica della privacy, ma senza una crescita della nostra consapevolezza sull’intero tema della riservatezza, nessun intervento avrà mai successo.
Bibliografia
- Dentro Facebook, Katherine Losse
- La conversazione necessaria, Sherry Turkle
- Big Data, Viktor Mayer-Schönberger e Kenneth Cukier
Sitografia
- Corriere.it
- ilsole24ore.it
- ilsole24ore.it/privacydifferenziale
- ilpost.it
- nytimes.com
- lastampa.it
- focus.it
- newrepublic.com
- wired.it
- theguardian.com
- discovermagazine.com
- sas.com
- propublica.org
- pnas.org




